- 扫描打开手机站
- 随时逛,及时抢!
故意说谎?哈佛大学提出ITI:模型真实性加倍,计算开销基本为零
2023/6/25 19:33:06 主编:孟泽
GPT的内部表示确实存在真实的信息,哈佛学者提出ITI将输出引导到事实的方向。
大型语言模型,例如那些经常在答案中输出错误信息的语言模型,可能会误导用户,这种现象也称为模型幻觉(model幻觉)。
直观上,语言模型在训练过程中肯定看到了正确的答案,但在推理过程中事实信息丢失了。
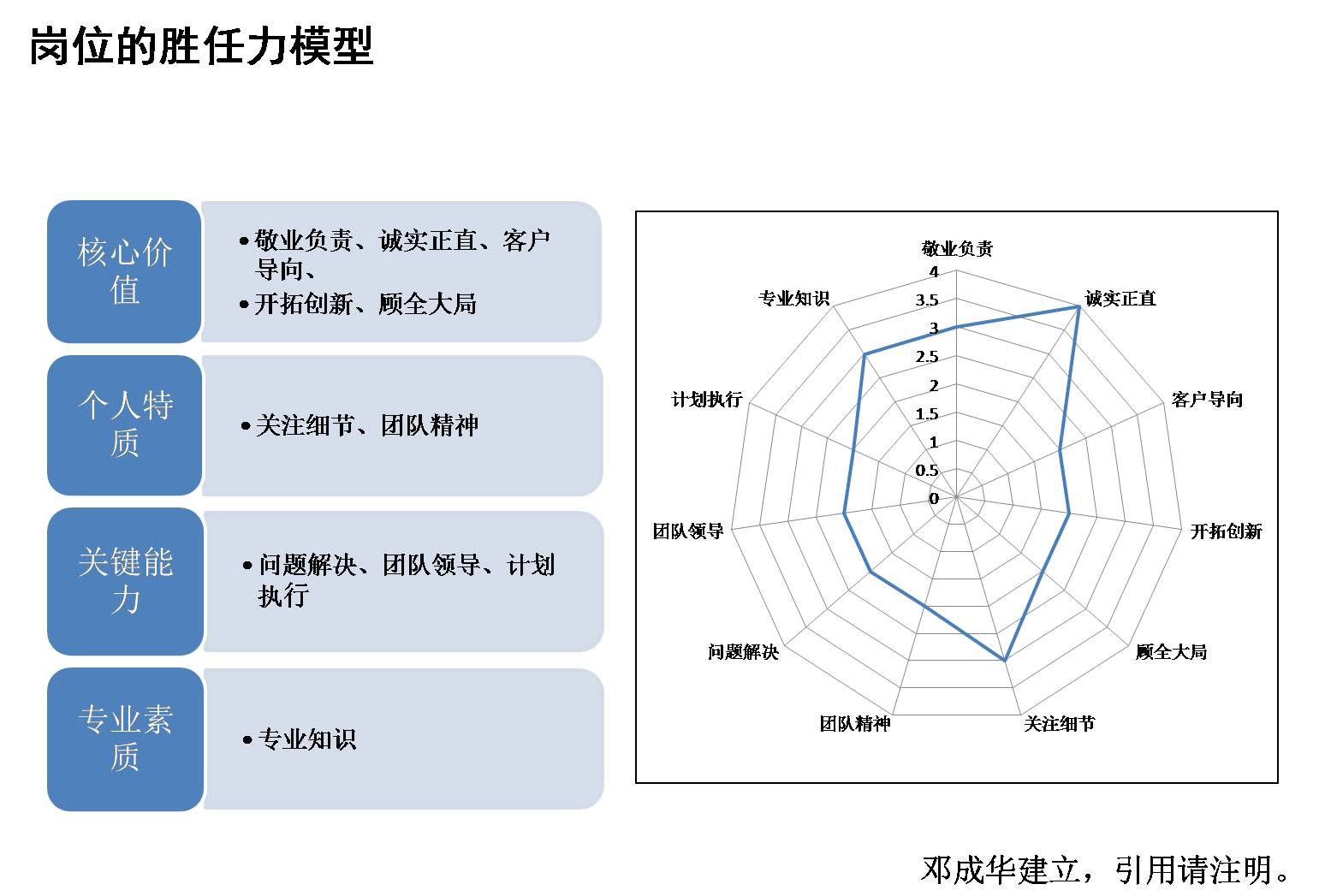
近日,哈佛大学研究人员提出了推理时间干预(-Time,ITI)技术,该技术将推理阶段的模型激活转向,引导模型输出向事实的方向发展。 干预结果显着改善了LLaMA模型。 基准性能,将模型真实度从 32.5% 提高到 65.1%
论文链接:pdf/2306.03341.pdf
代码链接:/
研究人员利用这种技术开发并开源了一个“诚实的 LLaMA”模型。
ITI还可以通过控制超参数来调整干预强度,平衡模型的真实性和有用性; ITI不修改原有模型,基本没有计算开销; 而且ITI不需要大量的标记数据,只需要几百个样本。 事实的真实方向是可以确定的。
研究结果表明,语言模型的内部表示中确实存在事实信息,但有时在生成时会选择错误的事实。
ITI让答案更加真实
在理解法学硕士的内部运作方面已经取得了进展,一个重要的主题是语言模型的激活空间似乎包含在推理过程中发挥因果作用的可解释方向。
基于这个想法,研究人员提出了一种增强语言模型真实性的方法,即推理时间干预。 基本思想是确定激活空间中与事实正确的句子相关的方向,然后在推理过程中将激活转换为该方向。 。
本文主要探讨如何控制模型的行为,在实验中使用了开源的LLaMA,和模型,但是该思想适用于所有GPT风格的系统,但是模型的内部激活和计算必须可用。
ITI 方法还需要一组标记的问答对来确定与模型说真话相关的注意力头和方向。
基本设置
在数据集选择方面,研究人员选择在生成答案时衡量语言模型是否真实。
该数据集包含 38 个类别(例如逻辑错误、阴谋和常见混淆点)总共 817 个问题,每个问题平均有 3.2 个正确答案、4.1 个假答案和 1 个由在线来源支持的黄金标准答案; 然后将答案重新排列为总共 5918 个问答对,每个数据样本都有一个二进制真值标签。
需要强调的是,这个数据集并没有涵盖“真相”一词的所有含义,也不可能全部涵盖。 研究人员主要关注如何避免“人类常见的误解”。 未来的研究方向将考虑扩展真实性的概念和评价。
从模型架构来看,大规模语言模型主要是层,每层的主要机制是多头注意力(MHA)和多层感知器(MLP)。

在推理过程中,首先将每个token嵌入到高维空间中,并以向量作为残差流的起点,最后将每个token解码为下一个token分布的预测; 在每一层中,MHA由多个MLP组成,MLP由独立的线性运算组成,MLP容纳了模型中的所有非线性运算。
探究真实性
为了提高神经网络的真实性,首先需要判断模型的激活空间是否存在真实性或事实性。
识别网络内部表示的常用工具是探针,其中分类器在网络激活上进行训练,作为探针来区分特定类型的输入或输出。
在事实性检测上,检测器主要检查注意力头的输出值,该输出值可以区分真假答案。
对于 中的每个样本,研究人员将问题/答案连接在一起,并取出最后一个 token 处的头部激活作为检测数据集; 然后将数据集按 4:1 随机分为训练集和验证集,并在训练集上拟合二元线性分类器,并使用验证精度来衡量每个头在基准数据上的表现之间的关系。
实验结果显示了注意力头的专用模式。 对于每层多个头,线性检测可以达到基线模型的精度,但仍然显示出强大性能的潜力。 例如,第14层达到了最高的精度。 18头实现,验证准确率83.3%
此外,可以看到各层之间的差异:信息主要在前面的层中处理,每层内部的少量注意力头脱颖而出。
通过类似于主成分分析(PCA)的方法,可以将激活空间中的维数降为2并可视化。 可以看出,“真实”的概念不仅存在于一个方向,而且存在于一个子空间中。
推理时间干预
上述探索实验描述了 LLM 如何在其注意头之间和内部处理与事实相关的信息,并提出了一种提高基准数据集性能的技术。
如果推理过程中的干预将激活转向“真实”,则网络有可能为基准问题提供更现实的答案。
首先,研究人员没有选择对所有注意力头进行干预,因为只有一部分注意力头与真实性强相关,而是只对前 K 个注意力头的结果进行干预,从而将攻击性降至最低。
第二个问题是如何确定用于变换特定头输出的激活的向量,因为真假句子的几何结构非常复杂,在选择变换激活的方向时,可以选择正向分离通过检测学习到的超平面。 交集向量,他也可以选择连接真假分布的平均值的向量。 不同干预方向的对比实验如下表所示。
探头方向是线性探头找到的方向。 在这个方向上的干预相当于对头部激活进行梯度下降,以最大化其预测为真的概率。
质量均值偏移的工作原理是,首先计算真实激活和假激活的平均值,然后使用从假平均值指向真实平均值的向量进行干预。
对比一致性搜索(CCS)是一种只知道内部激活的成对信息的方向。
研究人员对 CCS 进行训练,对每个问题采样一个真实答案和一个错误答案,由于 CCS 不接受带标签的输入,因此找到的方向有相同的机会成为真实方向和错误方向,然后使用标签来识别真实方向干预。
研究人员首先通过验证集上的检测准确性对所有注意力头的真假相关性进行排名。 以前K个头为目标集合; 然后使用训练集和验证集的激活来估计沿真实方向的激活的标准偏差。
ITI 是 MHA 的另一种形式,其中 是未选择的注意力头的零向量,相当于将激活沿真实方向移动 倍标准差。
对于每个下一个标记预测,整个过程会自回归重复,并且与解码算法的选择正交。
公式中有两个关键参数,即干预的注意力头数量K和干预的强度。 但是,目前还没有最优值的理论论证。 参数的影响只能通过实验探索并通过标准超参数扫描来确定。 最超值。
从计算效率的角度来看,无论干预多少个注意力头,ITI只会在每一层增加一个常数向量,可以认为干预的计算开销接近于零。
实验部分
用于比较的基线方法如下:
1.有监督微调(SFT)
SFT 是 RLHF 的第一阶段,研究人员使用问题作为线索,并使用交叉熵损失来驱动模型生成真实答案并惩罚错误的答案。
但如果仅采用上述操作,交叉熵损失和KL散度会急剧上升,因此需要交替进行问答的监督训练和开放网络文本的预训练。
2. 少量样本提示(FSP)
一些研究人员发现,与上下文蒸馏和 RLHF 相比,50-shot 提示也是 .
但由于提示策略的选择与推理时间控制方法正交,研究人员比较了使用和不使用 ITI 的少镜头提示。
3. 指令微调(IFT)
为了了解 ITI 如何使 IFT 模型更加真实,研究人员主要选择了两个基于 LaMA-7B 的模型( 和 )来执行 ITI 操作。
研究人员首先寻找控制干预强度的超参数最优值,最终确定K=48、=15
从结果来看,few-shot Tips 和 ITI 的结合取得了最好的效果。
在将ITI应用于指令微调模型的实验中,寻找并干预其真实性方向,可以看出ITI与基线相比,真实性显着提高,并且也可以应用于少样本提示或指令微调,但代价是CE损失和KL散度提升相对较低
参考: